The Absolute Worst Way To Read Typed Array Data with JavaScriptCore
Edit: as of September 13, 2016 Apple introduced a native API to manipulate Typed Arrays as part of iOS 10. This makes this whole article obsolete, if still technically interesting.
Oh man, where do I even begin.
Back when the HTML5 Canvas element was introduced by Apple to power some Dashboard widgets, the 2D Drawing Context supported a method to read the raw pixel data. This method was called getImageData() and it returned an ImageData object with a data array. This array however was not a plain JavaScript Array, but a new type called CanvasPixelArray.
This CanvasPixelArray behaved like a normal array for the most part, with some important exceptions: each element was clamped to values between 0-255 and the array was not resizable. This was done for performance reasons. With this restriction, the array could be allocated with a single memory region in the JavaScript engine.
I.e. the JavaScript engine's C++ source for getImageData() looked somewhat like this:
JSObjectRef GetImageData(int width, int height) {
// Allocate memory for the ImageData, 4 bytes for each pixel (RGBA)
uint8_t *backingStore = malloc(width * height * 4);
// Read the pixel data from the canvas and store in the backingStore
// ...
}In JavaScript you could then read, manipulate and write image data like this:
// Read a portion of the canvas
var imageData = ctx.getImageData(0, 0, 320, 240);
var pixels = imageData.data;
// Set the Red channel for each pixel to a random value
for (var i = 0; i < pixels.length; i += 4) {
pixels[i] = Math.random() * 255;
}
// Write it back to the canvas
ctx.putImageData(imageData, 0, 0);Manipulating pixels on the CPU is generally a bad idea, but using a plain old JavaScript Array would have made it prohibitively slow and memory inefficient. With the CanvasPixelArray it was at least feasible – this new array type deeply made sense.
Later, with the arrival of WebGL, the W3C realized that we need better facilities to deal with low-level binary data. CanvasPixelArray was a good start at making raw byte buffers faster, but other data types would be needed. So the WebGL draft proposed some new types in the same vain. Collectively, these were called Typed Arrays, because, other than plain JavaScript arrays, these had a fixed value type.
Modern JavaScript engines now support Typed Arrays in signed and unsigned flavors, with 8, 16 or 32 bit Integer values as well as 32 bit float and 64 bit float versions. E.g. Int32Array, Uint16Array and Float32Array.
At the same time, the good old CanvasPixelArray was renamed to Uint8ClampedArray. It now supports all the same methods as all the other Typed Arrays.
A very important addition introduced with these Typed Arrays is the fact that the actual data is not stored in the array but in a separate ArrayBuffer. The Typed Array itself is then only a View of this buffer. Furthermore, this buffer can be shared between different Views.
// Create a Uint32Array with 64 values. This allocates an ArrayBuffer with
// 256 bytes (64 values × 4 bytes) behind the scenes.
var u32 = new Uint32Array(64);
u32.length; // 64
u32.byteLength; // 256
// Create a Uint8Array, sharing the same buffer
var u8 = new Uint8Array(u32.buffer);
u8.length; // 256
u8.byteLength; // 256
// Modifying data on either View will modify it in all other views sharing
// this buffer
u8[1] = 1;
u32[0]; // 256
Every browser supporting WebGL or the Canvas2D context needs to be able to read and write the data of these Typed Arrays in native (C++) code as fast as possible. Say for instance you create a Float32Array with the vertex data of a 3D model in JavaScript. The WebGL implementation of your Browser needs to hand this data over to the GPU (via OpenGL or Direct3D) and - if possible - do it without copying.
Fortunately, as we established earlier, JavaScript engines only need to allocate a single lump of data for each array. A WebGL implementation can simply hand over the address of this data to the GPU and be done with it. E.g. an implementation of WebGL's gl.bufferData() might look like this:
void WebGLBufferData(JSObjecRef array) {
void *ptr= JSTypedArrayGetDataPtr(array);
size_t length = JSTypedArrayGetLength(array);
// Call the OpenGL API with the data pointer we got
glBufferData(GL_ARRAY_BUFFER, length, ptr, GL_STATIC_DRAW);
}There. Problem solved. Fast access to binary data without copying or conversion of some sort.
So, if all is good and well, what's with the title of this post then? Well, this is where the fun part starts. Buckle up.
Back in 2010 I started an Open Source project for iOS called Ejecta. It implements the Canvas2D and WebGL APIs in fast, native code and exposes it to a JavaScript runtime. Ejecta then lets you execute JavaScript code to draw to the screen using Canvas2D or WebGL. This is way faster than a browser, because it doesn't carry around all the bloat of a browser. It's a Canvas implementation without the HTML cruft around it.
As with all the Canvas implementations of modern browsers, Ejecta needs to read and write Typed Arrays as fast as possible. Ejecta uses JavaScriptCore (JSC), Apple's JavaScript engine to execute JavaScript code. I didn't specifically choose JSC. Rather, JSC is the only modern JavaScript engine that Apple allows you to run on iOS.
On modern iOS versions, JSC is available as a public API, meaning anyone who writes an iOS App in native code can use the API of JSC to execute JavaScript in their App. The JSC API is a pretty minimal layer that sits on top of JSC. It used to expose everything you'd want to do with JSC for your native code, but has hopelessly fallen behind in the last few years.
You probably know already where this is going: while you can create JavaScript objects, expose native C functions to JavaScript and do all kinds of object manipulation, you cannot access Typed Array data through JSC's public API.
This is an absolute show stopper for a WebGL implementation that attempts to use the JSC API. Note that Apple doesn't have this problem with their WebGL implementation in Safari/Webkit, because they are not limited to this public JSC API. They can dive deep into the JSC internals and can get that data pointer directly.
We can not.
So I wrote my own API for JSC to deal with Typed Arrays. You don't need much, actually: a function to get the data pointer and the length, a function to construct a Typed Array with a given type and a function to get the type of an existing Typed Array.
You can see my Typed Array API in the JSTypedArray.h on Github. It's pretty straight forward. Likewise the implementation for this (JSTypedArray.cpp) is only about 130 lines of code.
Now, adding your own API to a library provided by iOS is a big no no. Remember, these functions need to access the internals of JSC and Apple hates that. So I forked JavaScriptCore and provide my own JSC lib as part of Ejecta. The compiled version is about 7mb in size, which isn't all too bad. Still, it's a shame that we have provide our own library just for these 130 lines of code.
Of course I tried to get my API into the official JSC library. I opened a bug report on Webkit.org in 2012 and proposed my Typed Array API design. In the following 3 years not much has happened, other than some bike shedding and lots of silence, despite my best efforts to improve the proposal. Sadly, it seems I'm pretty alone with this problem.
Let me use this opportunity to rant about the Open Source-ness of JSC for a bit. You see, JSC is part of the Webkit project, which touts to be Open Source. And it's true, you can access most of the source code; it's licensed under the LGPL License. This license states that if you want to modify JSC, such as Apple does, you have to provide:
(...) all the source code for all modules it contains, plus any associated interface definition files, plus the scripts used to control compilation and installation of the library.
(emphasize mine)
Yet, the project files or scripts to compile JSC for iOS are curiously missing from the source code.
This wouldn't be a big deal if compiling JSC was easy, but it's absolutely not. I and many others have spent countless days building XCode project files for iOS. JSC is a huge project, comprised of many different parts.
Just for kicks, there's one step that executes an Assembler (written in Ruby, no less), that compiles a custom Assembly language at compile time. The result of which is compiled into the final lib and used internally by JSC.
Another step compiles an executable with an empty main() function. This executable links in some other functions. A script then runs over this executable file an gathers the addresses of these functions. Again, the result of this is compiled into the final lib.
You can see how this may get tricky to set up for a new platform.
Every time we want to update our JSC library, we have to set up this build process anew. We also need to conform to Apple's platform policies with each new iOS version. Namely 64bit support and Bitcode compilation.
The last one is where it gets funky. To use Ejecta on Apple's new tvOS platform, you need to compile your App with Bitcode enabled. This also means that every library you use needs to be compiled with Bitcode enabled.
Some brave people actually figured out how to compile JSC with Bitcode enabled, but we have no way to verify its correctness. With all the funky custom Assembly language and function pointer addresses used in JSC, I wouldn't be surprised if the compiled Bitcode is indeed broken.
And lo and behold, it probably is broken. When I tried to upload my tvOS App to Apple's AppStore, the "Processing" step failed. Apple's support doesn't know why.
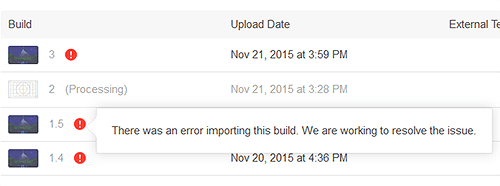
So, with no hope of seeing a Typed Array API in the official JSC anytime soon and my custom JSC lib "rejected" by Apple, there's only one option left and it's an ugly one.
Ejecta has to use the JSC lib provided by the OS and work around the missing Typed Array API somehow.
Ok, so we can't access a data pointer directly. Iterating over all values of the array separately in native code and storing them in a buffer should work too.
In addition to a GetProperty() function that reads a property with a given name of a JavaScript object, the JSC API actually provides a faster GetPropertyAtIndex() function. This function takes an integer and returns a JSValue.
Lets copy all the values from a Uint8Array.
uint8_t *buffer = malloc(length);
JSValueRef value;
for (int i = 0; i < length; i++ ) {
value = JSObjectGetPropertyAtIndex(ctx, jsArray, i, NULL);
buffer[i] = JSValueToNumber(ctx, value, NULL);
}Simple. And painfully slow. This takes about 1200ms per Megabyte on an iPhone5S.
Consider what the JSC API has to do behind the scenes for this GetPropertyAtIndex function: for each call, JSC needs to get the uint8 from the buffer and construct a new JSValue using that uint8.
Much worse though, the JSC API is designed to provide robust access from multiple threads. In order to make this work, each API call acquires an exclusive lock on the JavaScript Context. Imagine doing this in a loop, 2 million times per Megabyte and you'll see why this approach is a bad idea.
If we want to have some realtime animations, we only have 16ms per frame to do everything. And extracting data byte by byte from a Typed Array where I could previously simply get a pointer in constant time, is not something I planned for.
So we have to get the data out with fewer API calls. In the past though, before the arrival of Typed Arrays, JavaScript has been notoriously bad at dealing with big lumps of binary data. And the JSC API is stuck with the JavaScript of the past. The only other way to represent continuous, raw bytes is a String.
So I wrote a function to convert a Typed Array into a String.
Strings in JavaScript are stored somewhat like UTF16. It's not exactly UTF16, but the important thing is that each character of the string is internally stored in a 16 bit value. So we can store 16 bits or 2 bytes of our array in the String at a time.
The main trick here is to not iterate over the Typed Array in JavaScript, but instead call apply() on the String.fromCharCode() function. JavaScript's apply() calls a function in such a way that the 2nd argument to the function needs to be an Array or array like. Each array element is then treated as a separate argument to the function being invoked.
var func = function(a, b, c) {
console.log(a, b, c);
};
var array = new Uint8Array([1, 2, 3, 4]);
func.apply(null, array); // 1 2 3
There's a big caveat with this approach, though. In JSC function arguments are allocated on the stack and the number of arguments a function can take is hard limited to 64 thousand (0xffff to be precise).
So for big Typed Arrays we can't do the String conversion in one step, but rather have to subdivide the Array into smaller chunks. This however isn't much of a problem. If you remember from the beginning of the article, Typed Arrays are just a View on an underlying ArrayBuffer. Creating Sub-Arrays is pretty fast and will not copy the underlying data.
var TypedArrayToString = function(array) {
"use strict";
var chunkSize = 0x4000;
var u16Count = this.byteLength >> 1;
// Create a Uint16 View from the TypedArray or ArrayBuffer
var u16 = array instanceof ArrayBuffer
? new Uint16Array(array, 0, u16Count)
: new Uint16Array(array.buffer, array.byteOffset, u16Count);
// If this array has an odd byte length, we have to append the last
// byte separately, instead of reading it from the Uint16Array.
var lastByte = "";
if (array.byteLength % 2 !== 0) {
var u8 = new Uint8Array(u16.buffer, u16.byteOffset);
lastByte = String.fromCharCode(u8[u16Count * 2]);
}
if (u16Count < chunkSize) {
// Fast case - data is smaller than chunk size and the conversion
// can be done in one step.
return String.fromCharCode.apply(null, array) + lastByte;
}
else {
// Slow case - we need to split the data into smaller chunks,
// collect them in an array and finally join them together.
var chunks = [];
for (var i = 0; i < u16Count; i += chunkSize) {
var u16Sub = u16.subarray(i, i + chunkSize);
chunks.push(String.fromCharCode.apply(null, u16Sub));
}
chunks.push(lastByte);
return chunks.join("");
}
};Along with the native C function that invokes this function, takes the returned string and copies it into our own, native buffer, this takes about 60ms per Megabyte. About 55ms of which are spent in the JavaScript function. Much better than 1200ms, but still extremely slow.
After a while of pondering, it dawned on me. If String.fromCharCode can take the whole Array as function arguments - and is pretty fast at doing so - so could I with a custom function. Better yet, instead of just encoding 16 bits at a time in a character, I could use full 32 bit integers.
int32_t *CurrentDataPointer;
JSValueRef AppendDataCallback(
JSContextRef ctx, JSObjectRef function, JSObjectRef thisObject,
size_t argumentCount, const JSValueRef argumentValues[],
JSValueRef* exception
) {
for (int i = 0; i < argumentCount; i++) {
CurrentDataPointer[i] = JSValueToNumber(ctx, argumentValues[i]);
}
CurrentDataPointer += argc;
return NULL;
}This native function uses a global CurrentDataPointer (for the sake of this example) to copy the Array data into. It then simply iterates over the argumentValues, converts them to integers and stores them. The CurrentDataPointer is then incremented by the argument count - the amount of data already written.
This function is called (via apply()) from JavaScript, with the Typed Array spread out as separate argumentValues. For big Arrays this function needs to be invoked a number of times, because of the stack size limit. So it's important to keep track of the current write position.
What have we gained? Not much. Actually this performs worse than String.fromCharCode.
You see, String.fromCharCode doesn't need to acquire exclusive locks on the JavaScript Context when converting JSValues to native integers. It cheats by not using the JSC API's JSValueToNumber() function, but rather just casts the JSValue to an integer.
Excursion: How JavaScript Values are stored in JSC
On 64 bit systems, all JSValues are "pointers" with a 64 bit width. These pointers point to the actual JavaScript Object (a C++ class) in memory. However, for Numbers, true, false, null and undefined the pointer is not a pointer at all. Instead, the value is directly encoded in this 64 bit pointer.
How do we know the pointer is not a pointer but an immediate value? We use a few bits of this 64 bit value as tags. Current CPUs actually only use 48 bits for addressing memory (that's still enough for 256 Petabyte!), so we can be sure the upper 16 bits of the value are not used by pointers.
We can use some of these upper 16 bits to tag the type of this pointer. If some of these bits are set, the pointer is actually an immediate value.
Now, Numbers in JavaScript are either stored as 32 bit integer, or 64 bit double precision float. We don't have a problem to fit the 32 bit integer in our 64 bit, but the double value uses the whole 64 bit space. Well not exactly. Some floating point numbers are actually "invalid", NaN or Not a Number, such as the result when you divide by zero.
JSC uses one of these NaN values, one that is not produced by any other operation, to indicate that the 64 bit value is indeed not a double, but an integer. This is called NaN-boxing and is used by many different implementations of JavaScript, Python and other languages.
0x00000001 1846bf80 – None of the upper 16 bits are set; this is an actual
pointer to an Object in memory.
0x400a21ca c083126f – Some of the upper 16 bits are set and this is not a
NaN value, so it has to be a double. (3.1415)
0xffff0000 0000007b - All upper 16bit are set to indicate an int value.
Interpreted as a double, setting the upper 16bit would
always cause it to be NaN. The int is directly stored
in the lower 32 bit. (123)So, if we only care about Numbers, which we do since Typed Arrays only store numbers, we can circumvent calling the JSC API and decode this JSValueRef pointer by ourself. There's a bit more going on with this NaN boxing then I lined out here, but that's the gist of it.
Fun fact: 64 bit doubles can represent any 32 bit integer with exact precision. So we're safe to return a double in any case.
double JSValueToNumberFast(JSValueRef v) {
union {
int64_t asInt64;
double asDouble;
struct { int32_t asInt; int32_t tag; } asBits;
} taggedValue = { .asInt64 = (int64_t)v };
#define DoubleEncodeOffset 0x1000000000000ll
#define TagTypeNumber 0xffff0000
#define ValueTrue 0x7
if((taggedValue.asBits.tag & TagTypeNumber) == TagTypeNumber) {
return taggedValue.asBits.asInt;
}
else if (taggedValue.asBits.tag & TagTypeNumber) {
taggedValue.asInt64 -= DoubleEncodeOffset;
return taggedValue.asDouble;
}
else if (taggedValue.asBits.asInt == ValueTrue) {
return 1.0;
}
else {
return 0; // false, undefined, null, object
}
}With our own JSValueToNumberFast function in the loop of the AppendDataCallback, the time to extract 1 Megabyte is about 15ms. Not too bad. But we can do better.
The AppendDataCallback is only ever called with JSValue arguments storing 32 bit integers. So we know each JSValueRef is an integer. We don't have to test for it and we don't need to care about bools or doubles either. We can simply extract the lower 32 bit and treat it as an it. So how about this?
inline int32_t JSValueToInt32Faster(JSValueRef v) {
return (int32_t)v; // lower 32 bit of the 64 bit JSValueRef
}Remember how the AppendDataCallback just gets a plain C Array of JSValueRefs? It's essentially a big buffer of 64 bit values.
Contents of JSValueRef argumentValues[]
0xffff0000 00000000 - integer 0
0xffff0000 00000001 - integer 1
0xffff0000 00000002 - integer 2
0xffff0000 00000003 - integer 3
...Notice how we only care about the lower 32 bit of each JSValueRef. Essentially the lower 32 bit lane. There has to be something we can do to extract these integers faster instead of iterating one by one.
And for ARM CPUs there is. SIMD Intrinsics. Operations that are Single Instruction Multiple Data.
There are explicit SIMD operations that deal with this notion of lanes. Specifically we can use the following:
const int32x4x2_t lanes32 = vld2q_s32(argumentValues);This loads 2 lanes of 4 × 32 bit values each from our argumentValues. We can then extract the lower lane with lanes32.val[0], storing 4 × 32 bit values at once.
If we iterate 4 values at a time, we still have to care about any leftovers. For instance with 11 arguments, we can use this ARM intrinsic 2 times and have to extract the remaining 3 integers separately.
static JSValueRef AppendDataCallback(
JSContextRef ctx, JSObjectRef function, JSObjectRef thisObject,
size_t argc, const JSValueRef argv[], JSValueRef* exception
) {
AppendDataCallbackState *state=JSObjectGetPrivate(thisObject);
int32_t *dst = state->currentDataPtr;
int remainderStart = 0;
// On 64bit systems where ARM_NEON instructions are available we can
// use some SIMD intrinsics to extract the lower 32bit of each
// JSValueRef. Hopefully the JSValueRef encodes an Int32 so the lower
// 32bit corresponds to that Int32 exactly.
#if __LP64__ && defined __ARM_NEON__
// Iterate over the arguments in packs of 4. Load arguments as
// 2 lanes of 4 int32 values and store the first lane (the lower
// 32bit) into the dst buffer.
int argPacks4 = (int)argc/4;
int32_t *src = (int32_t*)argv;
for (int i = 0; i < argPacks4; i++) {
const int32x4x2_t lanes32 = vld2q_s32(src);
vst1q_s32(dst, lanes32.val[0]);
src += 8;
dst += 4;
}
remainderStart = argPacks4 * 4;
#endif
for (int i = remainderStart; i < argc; i++) {
*(dst++) = GetInt32(ctx, argv[i]);
}
state->currentDataPtr += argc;
return MakeInt32(ctx, (int)argc);
}Down to 7ms per Megabyte.
This is as far as it goes. Most of the time spent to extract the data is now spent in JSC where I have no access to.
7ms/MB is still disappointingly slow when you want to do real time 3D stuff, with large, changing buffers. However, not having to maintain and compile my own fork of JavaScriptCore simplifies things quite a lot.
Performance is still good enough to bring Xibalba to the AppleTV in 60 FPS. It's still in Review for the AppleTV, but you can play it in your browser or download it from the AppStore on your iOS device.
 Xibalba – A WebGL First Person Shooter
Xibalba – A WebGL First Person Shooter
I have published all my changes to Ejecta in the typed-array-clusterfuck Branch.
You can see the new API for Typed Arrays in the TypedArray.h (which mimics my original proposal quite closely). All the dirty implementation details and tricks are in the pedantically commented TypedArray.m.
As fascinating as this all was for me, keep in mind that the end result - 7ms/MB - is still 7ms slower than what we would have with a better API.
Please help me to get a real Typed Array API into JavaScriptCore: Comment on this Bug Report on Webkit.org.