Rewriting Pagenode
Today I released Pagenode – a project that I started 14 years ago. Pagenode began its life as a full-fledged Content Management System and now, after countless rewrites, became a simple library. Pagenode's journey mimics my own as a developer. Its current iteration expresses my desire for simplicity.
In 2004, after dabbling a bit with PHP and finally grasping MySQL I set out to build my own CMS. I previously looked at a lot of different CMSes on the market and found all of them to be lacking – some in code quality and overal structure (Wordpress comes to mind), others just felt overblown even back then and sported lots of weird "features" (e.g. Typo 3).
I wanted a simple, unified way to manage content. A single tree of nodes of different types, each derived from a base node type. Extensibility was paramount.
It took a few attempts to get it working. The way I structured my code back then looks embarrassingly amateurish to me now, but I learned a lot. I was especially proud of how my CMS stored the content tree in the database by using a Nested Set, complete with support for cut/copy/pasting of subtrees.
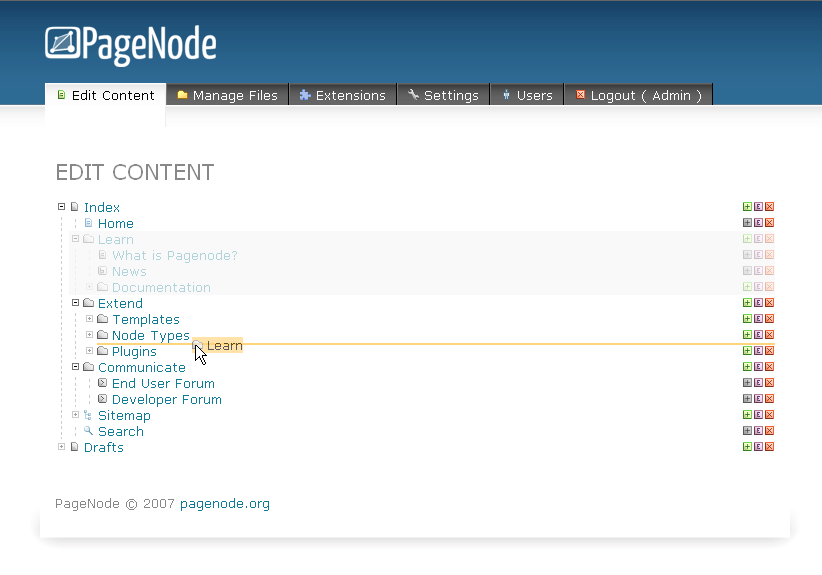
Content in my CMS was written in a minimalist markup language. Somewhat similar to the then non-existent Markdown, albeit with a smaller scope and worse ideas.
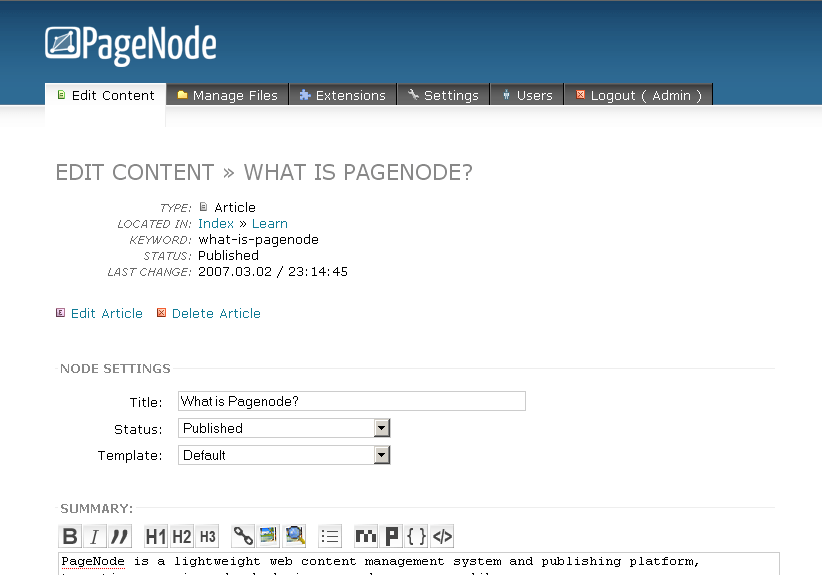
I added a bunch of more features that I thought were necessary at the time: a templating language, plugin system, localization support, etc. I also added a full fledged file manager, which was a lot of work on its own, but ultimately turned out useless – I uploaded most things via FTP and there was seldom any need for copying/moving/deleting files.
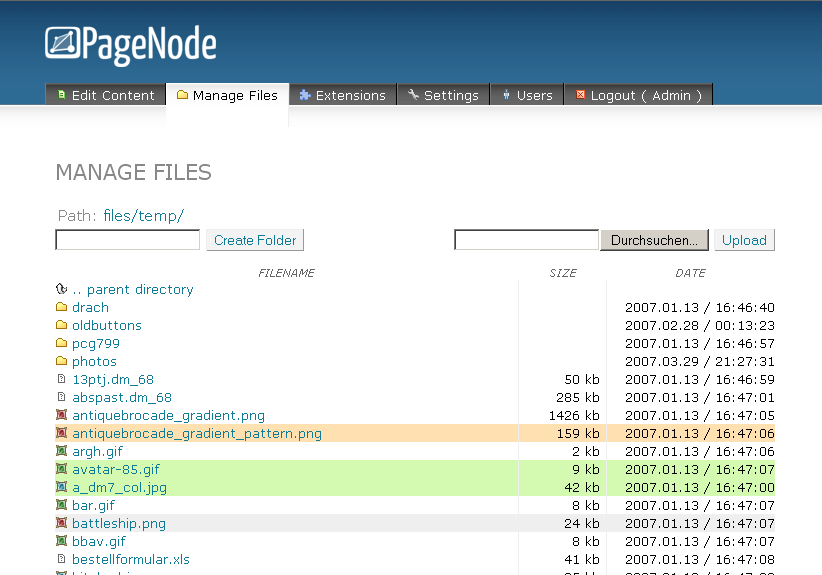
My CMS was almost complete and, as far as I was concerned, better than anything else on the market. I named the thing Pagenode and set out to release it "soon".
That release never came, but Pagenode still served my own needs nicely for more than a decade. The site for my HTML5 game engine (impactjs.com), my earlier gaming related site (chaosquake.de), this blog (phoboslab.org) and some others all ran on Pagenode.
During the years, it became apparent to me that some types of content just don't fit in a tree. My workaround was to create a new node type that hosts and manages the content by itself, instead of directly in the tree. It worked well enough, but eventually I had to re-think the whole approach.
Earlier in 2017 I started to think about re-writing Pagenode. I had learned a lot in the past decade and my disdain for complexity has only grown. There were a lot of things in Pagenode I could now do more elegantly, with less code in a clearer way.
So I re-wrote Pagenode.
I still wanted to use PHP and MySQL, because virtually every host supports it. PHP is still my "get shit done" language and in its not nearly as bad as people remember it.
My focus would be on collections of different types of content. No more tree like structure, but instead tagged nodes and a simple API to retrieve them. This allowed for a lot more flexibility, but still made the whole system a lot simpler.
With this narrow focus on collections of tagged nodes I soon noticed that I don't need a database. I could save nodes as JSON files, efficiently build and cache an index of all of them and filter directly in PHP.
So I re-wrote Pagenode again.
I build a system where you could define your own types by just sub-classing the base node type:
class Article extends Node {
const FIELDS = [
'related' => Field_URL::class,
'title' => Field_Text::class,
'subline' => Field_Text::class,
'titleImage' => Field_Image::class,
'body' => Field_Markdown::class
];
}This is all that was needed. The Admin interface would adapt automatically.
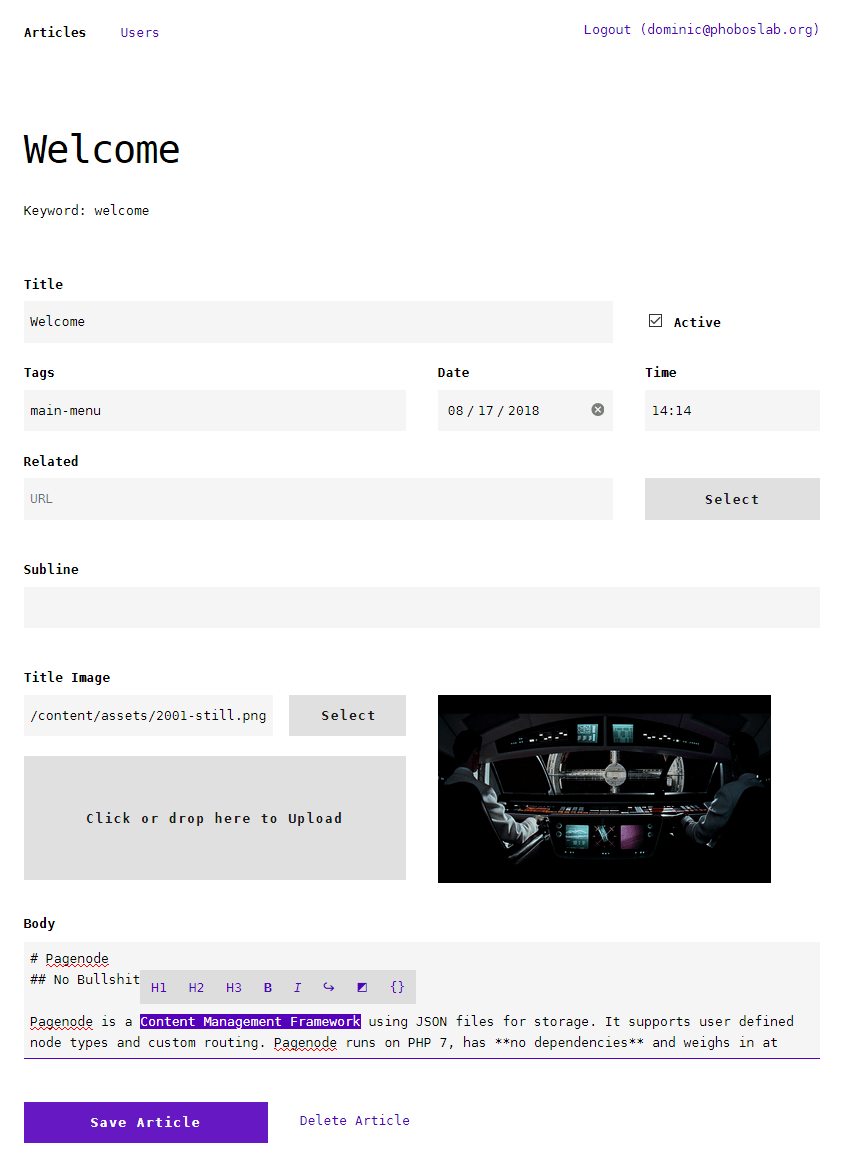
I spent a lot of time on the text editor, making drag+drop upload work, implementing a file browser and more. I brought all the content from my blog over into the new Pagenode and it worked great.
My CMS was almost complete and, as far as I was concerned, more elegant than anything else on the market. I named the thing Pagenode and set out to release it "soon".
(This version of Pagenode can now be found on github as pagenode-legacy)
Then I noticed that I actually don't want to write my blog posts in a textarea in a browser, but rather use my favorite editor. I also wanted versioning. And while I still could put everything in a git repository, work on my blog locally and then push to my server, nothing of the administration interface that I built would help me do that.
So I re-wrote Pagenode again.
This time Pagenode is just a library to load, select and filter plaintext content from disk. Nothing more. That's the version of Pagenode that I needed. It's extensible, it doesn't get in your way, it's fast, it's simple and it comes in a single PHP file.
Read more about Pagenode:
pagenode.org – official website and documentation
github.com/phoboslab/pagenode – source code