Time Domain Audio Compression at 3.2 bits per Sample
Audio formats typically fall into one of three categories: “lossless”, “complicated” or “bad”. After developing a simple image format last year, I tried to come up with an audio format that fits neither of these categories.
In other words: a format that is lossy, simple and quite ok. Naturally, it's called QOA — the Quite OK Audio Format.
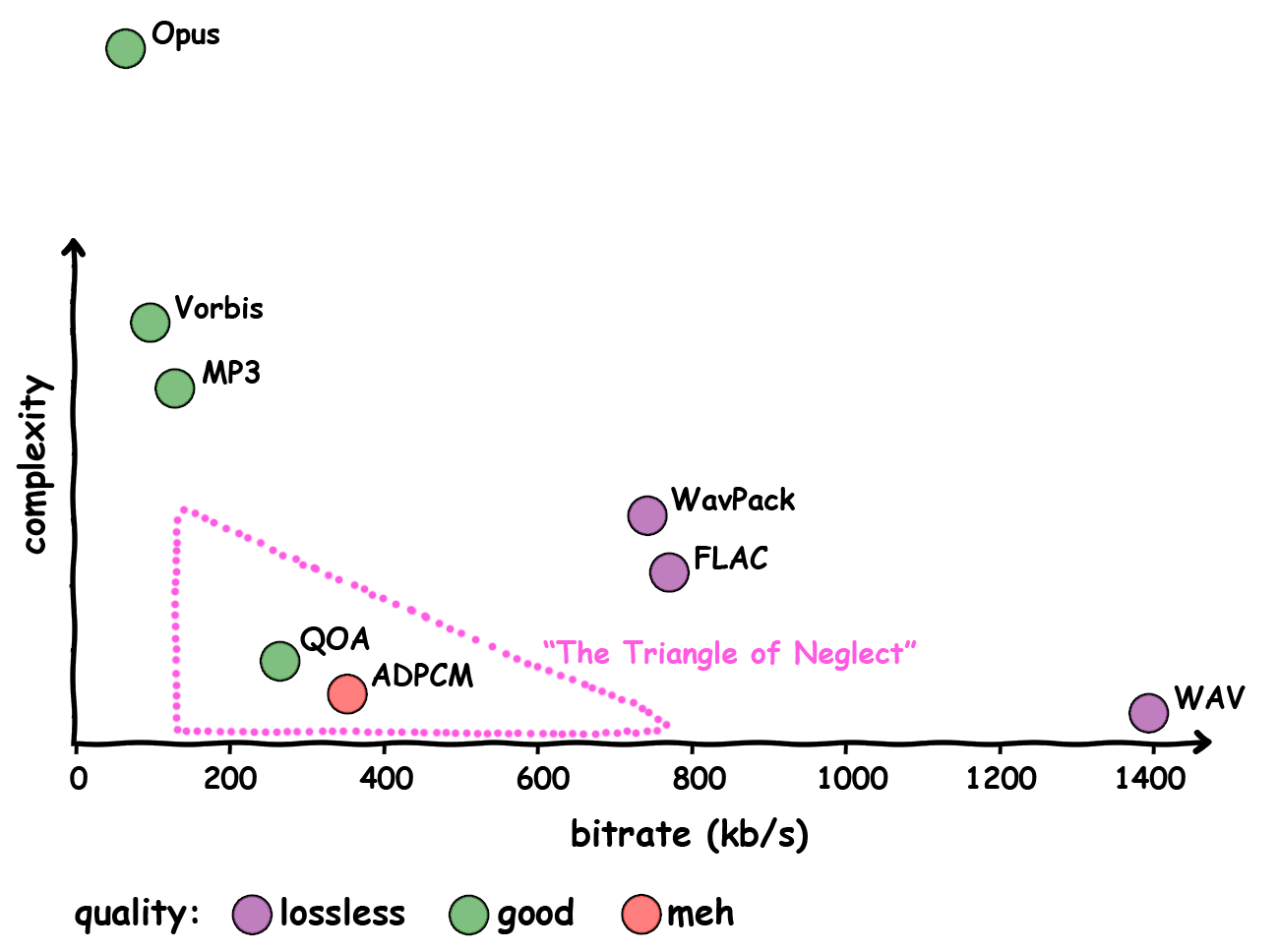 As hopefully evident by the generous use of Comic Sans: this chart
is subjective.
As hopefully evident by the generous use of Comic Sans: this chart
is subjective.
tl;dr: QOA is a lossy, time domain audio compression format with a constant bitrate of 277 kbits/s for Stereo 44100hz. 400 lines of C, single header, source on github, lots of audio samples here.
Why?
After having a lot of fun with the QOI image format I became interested in what the landscape for audio formats looks like. The story has some parallels to that of image formats lined out in the QOI announcement.
The 1970s and 1980s saw a lot of experimentation with very simple differential pulse-code modulation (DPCM) formats and then MP3, Vorbis and Opus came along, promising ever lower bitrates at the cost of spiraling complexity.
Unlike with image formats, storing anything other than the shortest sound snippets losslessly was unthinkable for decades, because of the (for the time still massive) file size requirements. The first lossless audio format to gain widespread adoption (FLAC) was released 6 years after MP3.
There still remains a huge gap between lossless codecs at ~800kb/s and MP3 at 128kb/s with seemingly little interest to fill it — apart from some speech and Bluetooth codecs that are much more complex than their quality would lead to believe and have as many patents as Qualcomm has lawyers (a lot).
The Triangle of Neglect
If you are building a game and want to play some sound effects and music, your options are quite dire:
- use Vorbis (preferably through stb_vorbis), unpack all sound effects at load-time into RAM as uncompressed PCM and spare some CPU cycles at run-time to decode music
- use 4-bit ADPCM and live with the bad quality
- build your own high-quality 8-bit ADPCM and live with the big file sizes
The last two options are still quite popular. Most GameCube games used their own 8-bit ADPCM format, EA invented a bunch of different ADPCM flavors for their games and so did many others. Likewise, it looks like 4-bit ADPCM is still being used in some applications when you need to play a lot of different sound effects. So you have a choice between poor compression and poor quality.
Lossless codecs offer no benefit as a delivery format in games and none of the popular perceptual audio codecs have low enough complexity for real-time decoding of many simultaneous sound effcts. There is one exception of course: Bink. A closed source solution made by the usual suspects and tailored to the games industry.
Bink Audio is a performance-oriented audio codec that is capable of perceptually lossless 10:1 compression with decode speeds closer to ADPCM than MP3 or Vorbis.
It's difficult to find more information on the Bink Audio Codec. It appears to operate in the frequency domain like MP3 or Vorbis, which comes with some inherent complexity.
A Short Overview of the Audio Codec Landscape
Audio compression schemes can be broadly divided into two different approaches:
Time Domain Codecs
Time Domain codecs go over the PCM data sample by sample. They try to predict the next sample and only store the difference (the “residual”) from this prediction. The prediction can be as simple as just assuming the next sample will be the same as the current one, or that the difference between samples will stay the same – i.e. that the “velocity” is constant for now (“2nd order predictor”).
ADPCM codecs typically do some variation of this. These are lossy codecs, as they store each remaining residual in 4 bits (as mentioned before, some variations with 8 bits per residual exist). Since these 4-bits only give you 16 different values to work with ADPCM also tries to predict the magnitude of the next sample and maps those 16 values to smaller or larger ranges accordingly.
MultimediaWiki has some good documentation on these formats. IMA_ADPCM is one of the more popular flavors of ADPCM.
Lossless codecs such as FLAC and WavPack go one step further with their predictions by running some filter over a block of (say 8000) samples to figure out how each sample correlates with the previous samples. This is called “autocorrelation” – i.e the correlation of the signal with itself. The coefficients that describe the correlation for these block are written in the file along with the residual for each sample. The residual in this case is simply what remains after all the correlation has been eliminated.
Assuming all the residuals are now quite small, they are compressed with a scheme that allows storing small numbers with fewer bits. In the case of FLAC rice coding is used; WavPack does something slightly different.
All in all FLAC is not a complicated format. Not quite 400-lines-simple, but far from the complexities of Opus. Looking at the code of libflac certainly does not give this impression – the FLACLoader of SerinityOS is a much more pleasant read.
If you're looking for an even simpler lossless codec, David Bryant, the author of WavPack, has another project going: SLAC.
WavPack itself is more complicated in that it does multiple passes of different decorellation filters and uses a bunch of other clever tricks that – even after studying the source code quite a bit – I can't fully grasp. In turn, it offers a lot more features and flexibility over FLAC. This includes a lossy compression mode, down to 2.4 bits per sample. Maintaining acceptable quality at this minimum bitrate comes at the cost of a lot of computational complexity. At 3 bits per sample the amount of work the en- and decoder have to do can be much more relaxed.
There are a lot more lossless audio codecs that operate in the time domain and a whole bunch more lossy ADPCM variants. But to the best of my knowledge, WavPack remains and outlier in offering lossy time domain compression with good compression ratio and good quality.
Frequency Domain / Transform Codecs
Encoders operating in the frequency domain take a block of time domain samples, figure out which frequencies are present, throw away frequencies that are unimportant (often determined by a psychoacoustic model, specifically auditory masking) and write the amount of each remaining frequency to the stream. A decoder reverses the process and creates a time domain signal using the encoded frequencies.
Most of these codecs use some flavor of DCT to do this transformation from time domain to frequency domain. MDCT is a popular choice. It transforms the samples in overlapping blocks using a window function.
This transformation, the windowing that has to be applied before and the subsequent psychoacoustic modeling requires some heavy lifting that is only ever described in an obtuse language that wallows in different foreign alphabets and single letter variable names. (Steven Wittens made a better version of this joke)
Virtually all modern codecs use some variation of this as their basis, often with some form of entropy coding (huffman or others) generously sprinkled on top. MP2, MP3, Vorbis, Opus, AAC, WMA and all kinds of recent telephony and Bluetooth codecs are some examples.
There is a reason for this widespread use: it works.
Opus specifically is excellent. It does it all, from extremely low bitrates to perceptually lossless. All streamable with very little delay. Though Opus' trick is to use two different codecs under the hood: one in the time domain, one in the frequency domain. Depending on the bitrate you get one or the other – or even both in a hybrid mode. It's a technical marvel.
The point is: these codecs are decidedly not simple. Neither conceptually nor computationally.
The Quite OK Audio Format
QOA's main objective was simplicity. Naturally, it is a time domain codec. It
does not transform samples, it has no psychoacoustic model, no entropy coding,
no stereo de-correlation, no floating point math and the decoder is free of
divisions (the encoder uses a division to figure out the encoded size for a
malloc()). The whole thing fits in 400 lines of C (plus comments).
QOA has a bunch of other nice properties:
- It's fixed rate, so trivially seekable by just jumping to the nearest frame offset
- Everything is 64 bit aligned. There's no bit-wise reading required
- It's theoretically streamable with just 20 samples delay (0.45ms at 44100hz)
- It does not cut off higher frequencies, like many transform codecs do
Quality
QOA has been designed to be transparent for the vast majority of audio signals. To my (admittedly aging) ears there's no detectable difference between the uncompressed original and the compressed QOA version.
There are exceptions though. For some sounds QOA can introduce a bit of noise that is audible if you wear headphones and turn up the volume. This is white noise, that many people, me included, find way less jarring than the typical pre-echo and metallic sounds that badly compressed transform codecs introduce.
As with any lossy codec some detail is lost along the way and QOA is no exception. If QOA is suitable for your application is a question that I cannot answer. Please listen to the QOA Test Samples to get your own impression.
I'm sure the quality of the encoder could still be improved by implementing noise shaping, pre-computing the best LMS weights for a whole block (for static files) or through other means.
Bitrate
The bitrate for QOA is only depended on the sample rate and number of channels of the audio signal. Each sample is encoded with exactly 3.2 bits. Together with the frame headers QOA compresses 44khz stereo to 277 kbits/s. This is about twice the bitrate of a “good enough” quality MP3 at 128 kbits/s.
Depending on your requirements you may be able to reduce the file size further by just lowering the sample rate. If that sounds like cheating, keep in mind that MP3 at 128kbit/s typically cuts off anything above ~16khz, too. If you would do the same for QOA – i.e. resample to 32khz first – you'd arrive at 201 kbits/s for stereo. As another example, speech at 8khz mono clocks in at 25 kbits/s.
Technical Details
For “CD quality audio” 44100 samples per second are stored with a
resolution of 16 bits per sample. A single sample therefore can have a value in the
range of -32768 to 32767. This sample-rate and bit-depth is considered to be
more than adequate to cover the full range of human hearing by anyone who
doesn't buy gold plated network switches to widen the sound stage.
(If you haven't read Monty's Why 24/192 Music Downloads are Very Silly Indeed or seen A Digital Media Primer for Geeks and Digital Show & Tell about this topic, you're in for a treat)
For QOA the sample-rate can be anything between 1hz and 16mhz, but it is limited to reproducing samples at 16 bit depth.
The whole encoding process works like this:
- predict the next sample
- calculate the residual (how far off the prediction from the actual sample is)
- divide the residual by some scalefactor to squeeze it into 3 bits
- store the scalefactor and the residual to the stream
Prediction
Like for other time domain codecs, the heart of QOA is in the prediction of the next sample. QOA uses a “sign-sign” Least Mean Squares Filter with 4 weights (“taps”). The prediction is simply the sum of the 4 weights multiplied with the 4 previous samples.
int qoa_lms_predict(qoa_lms_t *lms) {
int prediction = 0;
for (int i = 0; i < QOA_LMS_LEN; i++) {
prediction += lms->weights[i] * lms->history[i];
}
return prediction >> 13;
}In the encoder, the sample to encode minus the prediction gives us the prediction error or “residual”. This residual is then quantized (through the magic of a process called “division”) and later stored in the encoded data.
The quantized value is immediately dequantized again and added to the prediction to form the reconstructed sample. This quantize/dequantize step in the encoder is important, because it ensures that the en- and decoder always arrive at the same samples and therefore the same predictions.
int sample_to_encode = sample_data[si];
int predicted = qoa_lms_predict(&lms);
int residual = sample_to_encode - predicted;
int quantized = /* quantize residual (explained later) */;
int dequantized = /* dequantize quantized value */;
int reconstructed = qoa_clamp(predicted + dequantized, -32768, 32767);
qoa_lms_update(&lms, reconstructed, dequantized);The residual and the reconstructed sample are fed back into the LMS to update the
prediction weights. If the sample at history[n] is greater or equal 0, the
residual is added to weight[n], else it is subtracted from weight[n]. Note
that the residual can be positive or negative, so this will always nudge the
weights in the right direction.
We also rotate the 4 history samples with the reconstructed one. The oldest one is discarded and the newest one added at the end.
void qoa_lms_update(qoa_lms_t *lms, int reconstructed, int residual) {
int delta = residual >> 4;
for (int i = 0; i < QOA_LMS_LEN; i++) {
lms->weights[i] += lms->history[i] < 0 ? -delta : delta;
}
for (int i = 0; i < QOA_LMS_LEN-1; i++) {
lms->history[i] = lms->history[i+1];
}
lms->history[QOA_LMS_LEN-1] = reconstructed;
}Updating the weights ensures that our next prediction is more accurate than the previous one – that is, if the signal characteristics don't change much.
How much exactly the weights should influence the prediction is important: too little and your predictor is not adapting to a change in the signal fast enough, too much and you will miss-predict all over the place.
Note that the right shift residual >> 4 in qoa_lms_update() is just there to
ensure that the weights will stay within the 16 bit range (I have not
proven that they do, but with all my test samples: they do). The right shift
prediction >> 13 in qoa_lms_predict() above then does the rest. There is
probably some scientific method to figure this out exactly, but I used
good old trial and error to arrive at these values.
Quantization
Quantization is the process of mapping big values to smaller values. This “mapping” can be a simple division, which, if you caught the theme of this whole thing, is what QOA does. Almost.
QOA quantizes the residuals in “slices” of 20 samples each. The samples for each slice are divided by one of 16 different divisors - here called the “scalefactor”. The scalefactors in QOA are fixed and they become less accurate at the higher end.
int qoa_scalefactor_tab[16] = {
1, 7, 21, 45, 84, 138, 211, 304, 421, 562, 731, 928, 1157, 1419, 1715, 2048
};After the division we map values in the range of -8 to 8 into 3 bits (i.e we map
17 different values to 8). This is done with a lookup table, where each of the entries
in the qoa_quant_tab is an index into the qoa_dequant_tab:
int qoa_quant_tab[17] = {
7, 7, 7, 5, 5, 3, 3, 1, /* -8..-1 */
0, /* 0 */
0, 2, 2, 4, 4, 6, 6, 6 /* 1.. 8 */
};
float qoa_dequant_tab[8] = {0.75, -0.75, 2.5, -2.5, 4.5, -4.5, 7, -7};Like the scalefactors, this qoa_quant_tab becomes less accurate at the higher end.
For example, the values 6, 7 and 8 are all mapped to the same index 6. The
qoa_dequant_tab maps those 3 initial values back to 7 – the average of 6, 7 & 8.
In the actual code we don't use a floating point qoa_dequant_tab but pre-compute the
tab for each of the 16 scalefactors. This results in a lookup table of 16 * 8 values.
The scalefactor for each slice of 20 residuals is chosen by brute force: We encode each slice with each of those 16 scalefactors and then use the one that produced the least amount of error. The whole encoding loop of a slice looks like this:
for (int scalefactor = 0; scalefactor < 16; scalefactor++) {
int error_for_this_scalefactor = 0;
for (int si = slice_start; si < slice_end; si++) {
int sample = sample_data[si];
int predicted = qoa_lms_predict(&lms);
int residual = sample - predicted;
int scaled = qoa_div(residual, scalefactor);
int clamped = qoa_clamp(scaled, -8, 8);
int quantized = qoa_quant_tab[clamped + 8];
int dequantized = qoa_dequant_tab[scalefactor][quantized];
int reconstructed = qoa_clamp(predicted + dequantized, -32768, 32767);
qoa_lms_update(&lms, reconstructed, dequantized);
int error = (sample - reconstructed);
error_for_this_scalefactor += error * error;
}
if (error_for_this_scalefactor < best_error) {
best_error = error_for_this_scalefactor
best_scalefactor = scalefactor;
}
}Bit Packing
So we have quantized a slice of 20 residuals by one of 16 scalefactors. Each residual fits into 3 bits. Time to write the slice to the stream:
╭─ QOA_SLICE ── 64 bits, 20 samples ──────────────┬───────────/ /────────────╮
| Byte[0] | Byte[1] | Byte[2] \ \ Byte[7] |
| 7 6 5 4 3 2 1 0 | 7 6 5 4 3 2 1 0 | 7 6 5 / / 2 1 0 |
├────────────┼────────┼──┴─────┼────────┼─────────┼─────────┼─\ \──┼─────────┤
| sf_index │ r00 │ r01 │ r02 │ r03 │ r04 │ / / │ r19 |
╰────────────┴────────┴────────┴────────┴─────────┴─────────┴─\ \──┴─────────╯Here, I hope, it becomes quite apparent why one slice consists of 20 × 3bit
samples. Making a slice 64 bits makes it possible to load it into a uint64_t
and shift the individual residuals out one by one.
QOA stores 256 slices per channel into a “frame”. These frames are completely independent and can be decoded individually. A frame comes with a header that describes the audio format (sample-rate and number of channels) and contains the weights and the history needed to get the LMS going.
Finally, a QOA file is prefixed with a file header that contains the magic number
'qoaf' and the number of samples per channel in the file.
As you might have guessed, the file header is 64 bits, the frame header is 64 bits and the LMS state (weights and history) is 64 bits per channel.
struct {
struct {
char magic[4]; // magic bytes 'qoaf'
uint32_t samples; // number of samples per channel in this file
} file_header; // = 64 bits
struct {
struct {
uint8_t num_channels; // number of channels
uint24_t samplerate; // samplerate in hz
uint16_t fsamples; // sample count per channel in this frame
uint16_t fsize; // frame size (including the frame header)
} frame_header; // = 64 bits
struct {
struct {
int8_t history; // quantized to 8 bits
int8_t weight; // quantized to 8 bits
} lms_entry[4]; // = 64 bits
} lms_state[num_channels];
qoa_slice_t slices[256][num_channels]; // = 64 bits each
} frames[];
} qoa_file;The End.
What makes QOA work is 1) a reasonably good predictor and 2) storing the scalefactor for a bunch of samples explicitly instead of guessing the right one from context, like ADPCM does.
If you have a minute, please take a look at the QOA source code. You have seen much of it here already, but some details have been omitted for brevity. I spend a good amount of time to make the source as readable as possible and explain exactly what's going on.
Conclusion
Nothing here is new. I invented no revolutionary compression technique, I did not write a predictor that is better than existing ones. Everything here has been well established for the past 50 years.
I just put the pieces together. It took me a year to find the right ones, though.
You may not even care about the result. After all, QOA is slower than ADPCM, doesn't compress as much as MP3 and sounds worse than FLAC (duh). But I believe it fills a gap that was worth filling.
And I learned a lot. During the process I built countless experiments; some with very whacky ideas that amounted to nothing and some others that may be worth exploring further.
QOA is hackable. If you have some specific needs, you can modify it to store
2bit residuals or use a variable bit depth per slice. Changing the LMS
length is just one #define away.
What is presented here is just a compromise with an extremist view on simplicity.
Addendum
Higher Bit-Depths
As established above 44khz/16bit is more than adequate to cover the full range of human hearing. I do not discount that there are legitimate uses for higher bit depths (e.g. during production & mixing), but none of these apply to a lossy delivery format.
If you compress your intermediate files during production with QOA, you are doing it wrong. Use WavPack or FLAC.
Metadata
QOA files have no metadata. There's no point to having any. I do not expect anyone to re-encode their music library. QOA has been designed to be embeddable and in this scenario you most certainly know what files you are dealing with.
Endianness
Everything in QOA is big endian. Yes, virtually all CPUs these days are little
endian. Yes, there's a tiny of overhead for reading big endian int64_t on these
machines.
I pondered the endianess question quite a bit and came to the conclusion that
big endian is the sensible choice. You can read everything in QOA with a
read_uint64() function that shuffles big endian to the host endianess and then
mask & shift the individual values out. This is true for file and frame headers,
the LMS state and the actual data slices.
Storing slice bytes backwards just feels wrong. The layout on disk would make no sense. Explaining the backwards slice format would complicate a format that I worked very hard to simplify.
QOI got a lot criticism for it's endiannes. So, as a preventive measure – before you complain please ask yourself: does it really matter?